日报标题:这个纯「国产」的超级计算机系统,排到了世界第一
相关链接:中国「神威太湖之光」登全球超级计算机 500 强榜首
 huangkun
huangkun
一个比较详细的测试报告:http://www.netlib.org/utk/people/JackDongarra/PAPERS/sunway-report-2016.pdf
Top 500 排名第 1
Graph 500 排名第 2
Green 500 排名第 3,这个排名比较的是 性能 / 功耗
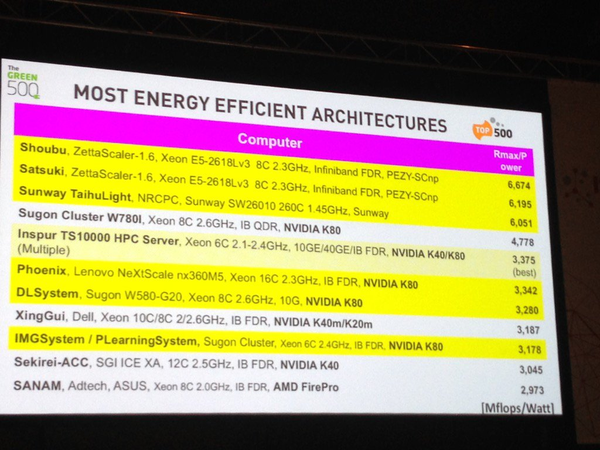
这东西其实倒腾了很久了,和天河二号是同时立项的,目标都是 100P。建造单位是国家并行计算机工程中心,属于军队研究单位,所以一直没有对外公布。本来预计是去年底就会发布的,一直拖到了现在。
神威系列的产品,其实一直都在部队内部运用,民用的不多,唯一宣传较多的就是济南超算的神威蓝光。获得国家最高科学技术奖的金怡濂院士,就曾经是神威系列的总设计师。
相比于机器本身,更值得期待是年底的 Gordon Bell 奖,这个 ACM 的 Award 是颁发给 HPC 领域的最前沿的应用的,代表着具体系统和实际应用结合的最高水平。中国目前还从未获得过,连入围最终阶段的应用都还没有(去年有个德国的应用在天河 2 上入围了)。而今年,在神威太湖之光上有 2 个应用(也有可能是 3 个)已经入围了 11 月份的 Gordon Bell 奖最终评审阶段,如果能够斩获最终的大奖,意义更大。
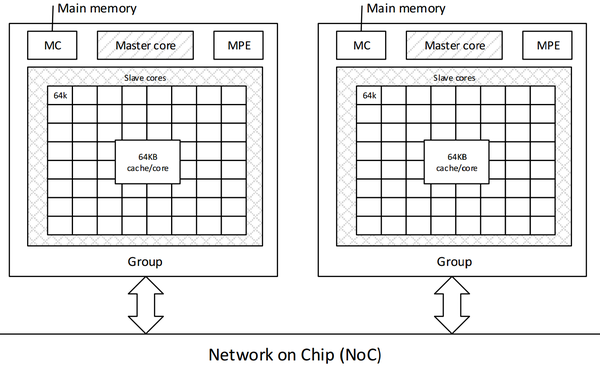
神威太湖之光的 CPU 架构是自己设计的, 计算单元包括两个部分,一个是主核,和普通的 CPU 类似。二是 8*8 的从核阵列。从核阵列相当于是 GPU、MIC 这一类的加速部件,可以直接访问主存,阵列行列之间可以进行快速的寄存器通信。
 Sean,什么时候毕业论文能被几百个教授一致通过呢。。
Sean,什么时候毕业论文能被几百个教授一致通过呢。。
白天看到这个消息非常振奋,当即就去找导师汇报!
我:“中国造了一台新超算,100PFlops!”
导师的第一反应是:“功耗多少?”
我:“15MW”
导师:“Holy sh*t!”
我:“他们没用 Intel 的芯片。”
导师:“oh that makes sense”
我也不是黑 Intel,但实在是 x86 架构的历史包袱太重了,想要实现 性能 / 功耗比的重大提升,这是一个迈不过去的坎。 我在 如何看待 19 岁少年想做出在目前 Intel 同等计算性能下降低 80% 功耗的全新电路系统芯片? - Sean 的回答 这个回答中就提到过,Rex Computing 的人在做的事之一就是砍掉 Cache,用 Scratch Pad Memory 取而代之。而在太湖之光的众核架构中的大量 Slave core 里面,采用了同样的思路,只保留了 instruction cache。data cache 用 Scratch Pad Memory 代替,避免了众核情况下的 cache coherence 带来的大量性能和功耗浪费。(Master core 里面有正常的 Cache),我觉得这是太湖之光实现高性能 / 功耗比的一个重要原因。 而且 Slave core 只支持 user mode,于是我猜测它在 TLB 上面应该也有精简。但目前 SW26010 芯片还没有详细的文档资料,所以这点我也只能猜测。
至于采用众核架构,可以说是大势所趋,美帝一些新的系统用的也是 Intel 的众核 Knights Landing 芯片,据说性能也很不错。
至于指令集,Jack Dongarra 在他的报告里特意强调和 Alpha 的指令集没有关系,所以哪怕神威前几代芯片和 Alpha 有渊源,但这次应该真没有……
然后更令我惊喜的是不光系统搭起来跑了 Linpack,而且还有三项应用入围了 Gordon Bell 奖的最终名单 (这个算是超算界最厉害的奖了)。充分说明太湖之光已经形成战斗力了啊!
最后冷静下来谈一谈不足之处: HPCG 的跑分。为什么 HPCG 跑分重要?因为它比 Linpack 更接近真实应用的场景,更能体现出内存系统的瓶颈。用一个汽车的比喻来讲,Linpack 的跑分更像是汽车的百米加速指标,而 HPCG 更像是到真实的赛道上去跑——这时候就不光是加大马力就能行的了,操控性等其他因素也很重要。
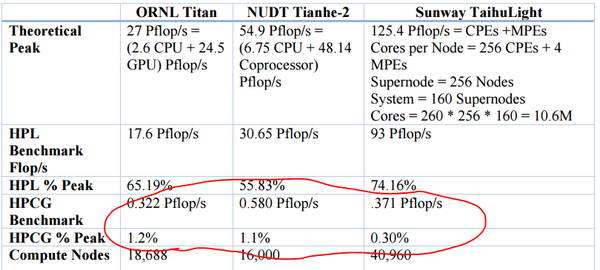
太湖之光在 HPCG 的测试下只达到了它 0.3% 的峰值性能,总的算下来还不如天河二号。说明其在 memory 和 network 的性能上存在很大的瓶颈。这其实还是挺不乐观的。
最最后还是不要掉以轻心,美帝这边正在奔着 exa-scale (1000 Pflops)努力,计划在 2023 年拿出性能达到 exa-scale,功耗小于 20MW 的超算。(美帝目前没有建造类似天河二的系统很大程度上是因为功耗的限制,放眼望去基本都是 10MW 以下的) 眼前就有 GPU 带来的变革,DARPA 为此也投资了不少黑科技的项目, 而且这个新闻一出,估计跟国会要钱更容易了…… 革命尚未成功,同志仍需努力啊!