日报标题:为什么有些音符合起来听,会有种怪怪的感觉?
 Mon1st,神经生物与行为学博士在读
Mon1st,神经生物与行为学博士在读
邓柯的回答中说
物质决定意识。音程是否让人感到谐和,是音程自身的自然属性决定的。
音程的谐和程度等于其频率比的数学简单程度,越简单、越谐和。
物质决定意识,但怎么样决定也得按照大脑运作的基本法。不能你拍脑袋说 1:3 比 8:9 简单,就决定了频率是这样比例的音程好听哇!神经机制呢?(明明有很多人研究过[3,4,5,6] 但是各位高票答案都没有引用,真是替你们捉急呀!)跨文化比较呢?(不支持单纯的频率比简单程度假说,见下文)
【数学比例简单 -> 某种物理现象 -> 文化加工 -> 和谐的音程好听】并非没有可能(实际上我猜很可能是对的,尽管仍然需要证明),但是【数学比例简单 -> 好听】 这个逻辑完全不通,属于听起来很厉害,实际上牵强附会的乱来。这相当于说腰臀比一定是 1:1,1:2,2:3 这样比较好看。(有趣的是,尽管这个类比由于感官不同等原因非常不恰当,对腰臀比的偏好同样是一个文化现象:在不同的文化区理想的腰臀比从 0.6 到 0.8 都有)
不和谐音程之所以听起来不和谐,其原理不可能是纯粹的数学 / 物理 / 生物,而一定包括了文化。下面搬运自我们是如何判断一段旋律是「悲伤的」或「欢快的」?
西方音乐理论中的一个重要概念是协调与不协调:协调 (consonant) 的音听起来令人愉快,不协调 (dissonant)的音则引人不悦[1]。有很多人认为这是由基本的物理原则决定的(甚至数学),但也有人认为这只是因为西方音乐的传统如此。[del]像这样的问题最后只能通过很不人道的实验来解决:培养一批从未接触过西方音乐的与世隔绝的儿童然后……[/del] 机智的人类学家们就找到了一批从未接触过西方音乐的人类群体:亚马逊丛林中的提斯曼人 (Tsimane') 来研究这个问题。文章标题简单易懂:
《亚马逊原住民对不和谐音毫不介意,揭示音乐感知的文化差异》[2]
作者辛苦地乘坐独木舟去到提斯曼人部落,给部落人听和谐或不和谐音(见下图)。
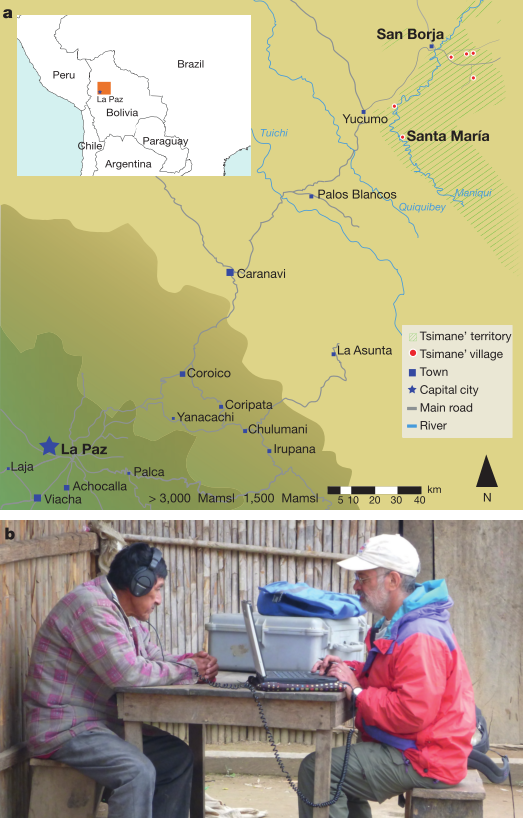
结果发现提斯曼部落的本地人对和谐或不和谐音同样喜欢。提斯曼人也有自己的音乐,但没有发展出对和谐音的偏好。这一实验结果轻松证明了和谐音比不和谐音“和谐”只是一个文化传统。
会不会是因为原住民听耳机感到新奇(或者因为交流不畅)因而没有报告原本会有的偏好呢?答案是不会,这里贴一下实验结果好了:
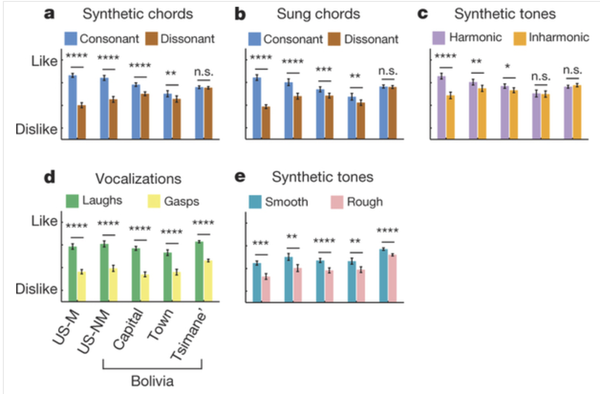
上面的柱状图代表被试对音乐的喜欢程度,越高越喜欢。每一组最右边是提斯曼原住民。(a)和(b)是协调 / 不协调和弦,可以看到美国人对协调和弦的偏好最明显,而提斯曼人则没有偏好。作为控制,比起喘气声,所有人都更喜欢听到笑声(d);比起粗糙的声音,所有人都更喜欢平滑的声音(e)。
下面是闲聊时间
我们对很多东西有很好的直觉。直觉可以用来指导,但绝不能替代,严肃的科学研究。用直觉宣布“我的理性告诉我简单的数字比例是美的”,是为玄学。用直觉来得到“某些简单数字比例的音程因为某种原因得到人类听觉系统的偏好”这一假说,然后设计实验去验证或推翻,是为科学。
[1] McDermott, J. H., Schultz, A. F., Undurraga, E. A., & Godoy, R. A. (2016). Indifference to dissonance in native Amazonians reveals cultural variation in music perception. Nature, 535(7613), 547–550.
[2] Stefano, N., & Bertolaso, M. (2014). Understanding Musical Consonance and Dissonance: Epistemological Considerations from a Systemic Perspective. Systems, 2(4), 566–575.
[3] Fishman, Y. I. et al. Consonance and dissonance of musical chords: neural correlates in auditory cortex of monkeys and humans. J. Neurophysiol. 86, 2761–2788 (2001).
[4] Tramo, M. J., Cariani, P. A., Delgutte, B. & Braida, L. D. Neurobiological foundations for the theory of harmony in western tonal music. Ann. NY Acad. Sci. 930, 92–116 (2001).
[5] Bidelman, G. M. & Heinz, M. G. Auditory-nerve responses predict pitch attributes related to musical consonance-dissonance for normal and impaired hearing. J. Acoust. Soc. Am. 130, 1488–1502 (2011).
[6] Bowling, D. L. & Purves, D. A biological rationale for musical consonance. Proc. Natl Acad. Sci. USA 112, 11155–11160 (2015).
 赵思家,UCL神经科学本科、计算机硕士、博士在读
赵思家,UCL神经科学本科、计算机硕士、博士在读
其实 @Mon1st 的答案已经基本回答了这个问题,我换个姿势来讲一下。
小学音乐教室的墙上有一排大字我印象很深刻:「音乐是世界通用的语言」。即使语言不通,文化不同,拿起乐器,我们也能通过曲调来产生共鸣。除了音乐所带来的情绪反应,似乎我们对「悦耳」的定义也是共通的。那到底是什么让我们觉得「悦耳」呢?为什么人类有这样的共通性?这是不是天生的呢?
过去,大多数科学家认为这是天生的,也就是 @邓柯老师的答案,认为是大脑的出厂设置就是将这些音程设置为悦耳的。或说,西方音乐中的这一特征(有些音程听起来和谐,有些听起来不和谐)(这也是很多人为什么对听觉神经科学感兴趣的原因。音乐本身可以说就是一个很独特的存在,为什么要有音乐?在人类文明发展之前,音乐有什么用?它既不能帮我遮风避雨,也不能让我逃开危险,更不能强身健体。但音乐的确存在,而且人类在音乐上的天分实在是令人惊讶。音乐的存在,本身就是神经科学中一个很有意思的话题。在此不深谈。)
但上个月 28 号(2016.7.28)的《自然》封面文章 (McDermott et al. 2016) 提供了直接证据:音程是否让人感到和谐,是后天的文化环境决定的。
所以 @邓柯的答案(「物质决定意识。音程是否让人感到谐和,是音程自身的自然属性决定的。」)是不准确的。但这也是情理之中,因为这是才出来的科研结果。邓老师不是专门研究听觉神经科学的科研工作者,所以可能在这方面的信息会有延迟是很正常的。
邓老师的答案非常完美地展现了传统上我们对「这个音程听起来很协调(consonant)」的理解。相信你去问老师(生物、心理或是音乐),这应该是标准答案。但,科学家的工作就是不断地质疑之前所得的知识,接受「我的理论需要被人超越」。
不和谐音程使人感到不和谐的原理是什么?
首先,什么是音程?维基百科:「在乐音体系中,音程是指两个音的高低关系,或两音之间的音高差距。」
这里我们研究的主要是‘和弦音程’,就是两个或多个同时发生的音符。
「有些音程听起来令人愉悦,有些音程却令人感觉突兀、不悦耳。」
在学术上(听觉神经科学和音乐心理学上),前者叫做谐和的(consonant),后者叫做不谐和的(dissonant)(见下图)。

图 1:西方音乐中谐和(consonant)和不谐和(dissonant)的和弦。截图自 Bones & Christopher 2015.
音乐家们也利用这些特征来谱写带有不同情绪的乐曲。譬如说,谐和的音一般听起来是愉快的、喜气洋洋的。譬如说星球大战主题曲开头,就使用 perfect 5th 来创造激昂,充满斗志的曲调(非专业,请轻拍)。而不协和的音往往有相反的效果,可以说不谐和的音会让大脑觉得感到意外,不稳定——这会让曲调有种‘紧张感’。(跪求轻拍)
那到底为什么有这样的规律呢?这种「谐和」是不是有生物基础的呢?换言之,西方音乐中的这一特征,是不是反映了大脑的一些基本设置,或说其本身就有基础性的重要性,只是我们只是在音乐中发现了它而已?细思极恐有没有。因为种种原因,很多科学家认为,这肯定背后有大秘密。
就像 @邓柯所提,这背后有明显的数学逻辑。而正是因为这个数学逻辑,让科学家更是坚信,这多半是天生的,绝逼不可能是巧合。
来自 MIT 的听觉神经科学家 Josh McDermott 是在这方面的「优秀答题者」。
** 这部分内容中英混杂,还未梳理干净,可读性较低,可以跳过 **
我们现在所猜测的相关原理,在 McDermott et al. 2010 这篇 Current Biology 中有一个很好的概括(我懒得翻译啦!)。反正为了测试到底声音的什么特性和谐和性有关,Mcdermott 测试了 250 名美国学生,发现人们认为没有 beats 的并且有 harmonic spectra 的声音更好听。但和对谐和的偏好相关的因素只有对 harmonic spectra 的偏好。同时对 harmonic spectra 的偏好也被发现与被试者的音乐教育长度相关。
所以,他们总结道,对谐和的感知应该是由「和弦中的音的泛音重叠多少」所决定的 (McDermott et al. 2012)(见图 2)。In the case of the dissonant tritone (A), the harmonics of the combined spectrum are irregularly spaced and therefore inharmonic. In the case of the consonant perfect fifth, the harmonics of the combined spectrum are regularly spaced and in some cases perfectly coincide (violet bars).
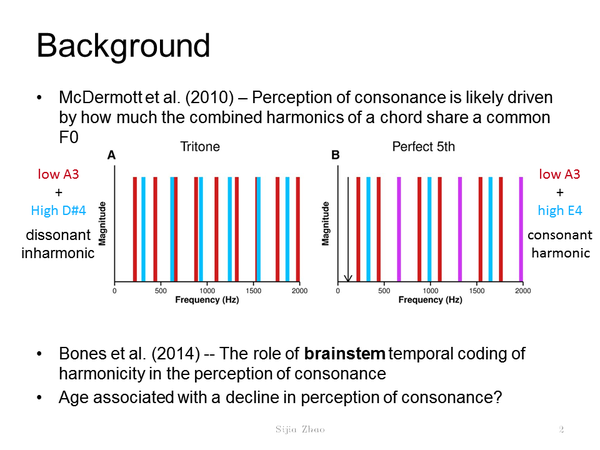
图 2:谐和的感知应该是由「和弦中的音的泛音重叠多少」所决定的(取自我自己的周会 ppt)
来自诺丁汉大学的 Bones et al. 2014 进一步发现,脑干中的 inferior colliculus 在编译泛音上有重要作用(The harmonic structure of a chord is temporally coded in the inferior colliculus.)。并且,this neural temporal coding of harmonic structure predicts individual differences in the perception of consonance in young normal hearing subjects.
虽然有些没头没尾的,但针对 consonance 的研究其实比较有限,比较靠谱的研究都还停驻于心理物理学上。脑电图和核磁共振成像方面似乎还没有?
** 可以从这里继续阅读 **
但这种普遍性会不会是因为大多数的(有话语权的)科学家本身都是听西方音乐长大的,而且所接触到的被试者,都是听着西方音乐的长大呢?
如果这个谐和的感知是天生的,那么无论有没有听过西方音乐,人们听到 perfect fifth 就会觉得好听,听到 tritone 就会觉得不好听。
但随着战争和殖民、以及现在的全球化,很难找到一个「完全没有受到西方音乐的影响」的群体。人类学家 Ricardo Godoy 发现马逊的一个超级封闭的小村庄 Tsimane 里,当地人都没有受到西方音乐的影响。他们的音乐非常单调,而且只有单音演奏,从来不会多人同时和声。
这样的群体,对于测试「音程的谐和性是否是天生的」简直是完美的文化 control 组!所以 McDermott 设计了一个非常简单的实验(我敢打赌,这应该是这几年发表在自然上最简单的一个实验了):给被试者放不同音程的声音,然后让他们评分到底「悦耳不悦耳」。结果也很清晰,在美国长大的被试者们(对照组)在听这些声音时,不谐和的声音明显就是不悦耳,谐和的声音就是悦耳的,但 Tsimane 的村民认为这些声音的悦耳性都一样,没有区别——说明谐和性是受音乐背景所影响的——这是后天的。

图 3:测试 Tsimane 居民的「实验环境」。McDermott 提供。右边那个男的不是 mcdermott,应该是 Godoy。
也就是说,你听到这个音悦不悦耳,是由你从小到大所听的音乐所决定的。那到底大脑是怎么决定谐和性的,神经科学上还不清楚。
如果你是普通读者,阅读到此即可。这个结果非常直接简单,没必要贴图来让你觉得「好科学啊,但看不懂」。
如果你想了解更多,请阅读原文(McDermott et al. 2016)。这个研究非常的简单也非常的优雅。他们设计了一系列的实验来控制对照组。会不会 Tsimane 的居民对 harmony 的感知有问题呢——检查了,并没有问题。会不会 Tsimane 居民对声音的情绪理解与我们不同呢?——测试了,没有问题。等等等……
我非常非常仔细地阅读了这篇论文,真的是无懈可击。(其实从 Mcdermott 平时不苟言笑就能猜到出来他是多么的严谨)。
写完了之后发现网上已经有不少相关的科普文了,请大家参考:
The Surprising Musical Preferences of an Amazon Tribe
Culture, not biology, decides the difference between music and noise
我已经把这篇论文的封面作为手机封面,每天舔屏。(导师看到后说我是个变态粉丝。)
这答案没头没尾的,没有结构,以后看到了相关论文,再来更新。
参考文献:
McDermott, J.H., Schultz, A.F., Undurraga, E.A., Godoy, R.A., 2016. Indifference to dissonance in native Amazonians reveals cultural variation in music perception. Nature advance online publication. doi:10.1038/nature18635 (这个就是上面提到的新文章)
McDermott, J.H., Lehr, A.J., Oxenham, A.J., 2010. Individual Differences Reveal the Basis of Consonance. Curr Biol 20, 1035–1041. doi:10.1016/j.cub.2010.04.019
Fritz, T., Jentschke, S., Gosselin, N., Sammler, D., Peretz, I., Turner, R., Friederici, A.D., Koelsch, S., 2009. Universal Recognition of Three Basic Emotions in Music. Current Biology 19, 573–576. doi:10.1016/j.cub.2009.02.058
Marin, M.M., Thompson, W.F., Gingras, B., Stewart, L., 2015. Affective evaluation of simultaneous tone combinations in congenital amusia. Neuropsychologia 78, 207–220. doi:10.1016/j.neuropsychologia.2015.10.004